

Synopsis
Short builds enable responding to change, continuous code improvement, and keeping your customers happy. When the build slows beyond certain thresholds, there are predictable responses by a team that lead to slower builds, lower code quality, and continuous code rot.
We’ll look into why this is, why it is worth investing in speeding up the build, and provide some ideas on things you might try to improve the speed of your builds.
Introduction
Working with a new team, many of the early questions center around the issue of build times. As a coach, I often join an existing project. My answers to are typically viewed as at best unrealistic, or at worst lunatic. Before giving a direct answer, let’s begin with some definitions and guidance to make sure it’s clear what I’m talking about.
Build?
What do we mean by “build” here? How long does it take after I’ve attempted to share my work with my colleagues before I get confirmation of success or failure?
This definition is anemic, but sufficient for our purposes. At the team level, my preferred measure is: “What is the time from commit to live in production?” For now, let’s keep to commit-level verification. A broader question worth asking is “How long from the inkling of an idea to verified learning?” However, if we cannot answer the smaller question, fixing the larger one might be out of reach at the moment.
What is Commit?
“When I am ready to commit, here’s what that means to me (in this description I’m using git):”
-
I think I have something worth integrating with my team members.
-
I run at least the commit-level test suite locally.
-
I commit locally.
-
I pull and merge changes committed by my team members into my local version.
-
If I pulled changes without merge conflicts, I jump back to step 2.
-
If there are merge conflicts, I take care of them and return to step
-
I push my changes.
-
I watch the build while doing “other useful stuff” such as thinking of more negative test cases, determining another vertical slice I can work on, etc.
What About Branching?
"Most recently, and even when I started using CVS back in 1989, I practice trunk based development. Originally it was ignorance. More recently it was because the hidden costs of delayed integration seem to greatly outweigh much of the value of feature branches. However, while that is a controversial position, it misses a key point. The point is frequent integration. If you are not using trunk-based development, but are frequently integrating with your other team members, that's what is essential. If you are trunk-based but not committing often, that's going to lead to issues."
Why is this time crucial?
How long does it take after I’ve attempted to share my work before I get confirmation of success or failure? That’s the time under discussion. In reality, whatever that time, I wait for that at least twice that time, and possibly much more. Why?
First, I ran the commit-level tests before I considered committing. If I pull and there are no other changes, then I have one more commit-level sequence from the build server. If I pull updates, then that’s 3 times. If there are several people pushing at the same time, then we might need a commit token for the team.
Build Pipeline Commit Stage
The commit phase of a build pipeline involves several steps:
- Pick up the changes
- Compiles
- Runs commit level tests
- Packages
- Takes the resulting deployable-unit and archives it for the remainder of the pipeline
- Triggers the next stages in the build pipeline. Note, this doesn’t mean the build is finished, it continues on possibility to deployment and maybe even release.
Is this time too long?
Without a direct number, here are a few heuristics you can use to gauge if the current time is too long. You want “yes”:
- Can I run commit-level tests many times a day to check the state of my local changes?
- Lunch just around the corner? Can I safely run the commit-level tests and share what I have?
- End of day, end of week. Do I share my work anyway because the feedback is quick enough?
- Are builds successful most of the time? I am surprised when I come in to a failed build? (No early morning blues.)
- Do I integrate often with my colleagues, not hesitating for fear of the time it will take?
- I do not feel compelled to skip a step for a “quicker build” because it’s already fast enough?
If there’s reluctance to share, or to try a small experiment, then the commit-phase transaction cost might be too high (there could be other social reasons as well). If time is the issue, is this because it takes too long, or because it is unreliable, or even both? Here we are focusing on time, but we mention reliability later.
Slow Build Woes
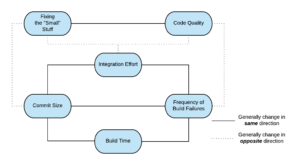
When the pain of building is high, you will integrate less frequently, which leads to larger and larger chunks of work needing to integrate. This sets up a positive (as in increasing) feedback loop in the build time. It also generally leads to more frequent build failures, which reduces the frequency of commits, leading to more difficult integration. It also makes small improvements expensive, which means that they don’t happen, leading to messy code, which increases cycle time.
Are we Practicing Continuous Integration(CI)?
Martin Fowler defines CI as everyone on a team merging and committing with each other at least once per day. This definition has aged and modern practitioners, myself included, consider this too infrequent. I have joined many projects where once a day was impossible, so we’ll use this definition as a line in the sand.
The goal is not CI. We want the possibility for validated learning, continuous flow of value to end users, noticing mistakes early and often, and being able to build a system incrementally over time. CI is one tool that tends to support those goals. Not integrating often tends to make those goals less likely. So a quick leading indicator of problems is whether the team can and is practicing CI.
Let’s use Martin Fowler’s definition for an example. Consider a 10 hour day (some people start early, some stay late). Assuming the worst case for waiting, all contributors attempting to commit at the same time, how long would it take for everybody to get feedback?
Before going on, one more assumption: We don't run builds in parallel, we wait. Why? If a number of builds fail, how do we know what caused the build to fail? While it’s possible to make this determination, because it could just as easily be one commit, the other, or their interaction, it’s more difficult to do so. And when the build fails, the whole team (should be) blocked. We can use tooling to run individual commits in parallel, where the second commit runs with the first commit, the third with the first, second, third, and so on. This is agood option and there are tools that do that. However, as commits tend to be distributed, we can do the calculations based on a simple first-in first-out model for some quick numbers.
With a team of 10 people committing, and a 10-hour day, 10 commits at the beginning of the day will finish by the end of the day if the “build” time is 1 hour, assuming 100% build success. That satisfied Martin Fowler’s definition.
"There's another glaring issue with this example. Nobody actually integrated in this scenario. However it provides some simple, basic numbers."
How about the wait times for feedback? The first person will wait 1 hour, the second 2, the 10th 10 hours. So the average wait time is 5.5 hours (the sum of 1 - 10 divided by 10). In reality, commits are distributed. If they are evenly distributed throughout the day, then the wait time will equal the build time of 1 hour. So the wait time averages between 1 and 5.5 hours.
Build time versus commit size
As the build time increases, the likelihood of someone committing diminishes. Rather than committing at the end of the day, s/he will commit in the morning, or do a bit more before committing because the transaction cost is high. This tends to batch work up, which increases the likelihood of integration issues. Larger batches increase the footprint of a change. Add in practices like refactoring or the “religion of conservation of file names”, and the chances of developers touching the same file increases.
As a real-world example, I joined a project where their successful build time was 90 minutes. Furthermore, the build failed 70% of the time (or a 30% success rate). The number of contributors varied but was around 20. The success rate was so low it was a contributing factor to the effective build time. A simple way to calculate the effective build rate is to divide the success percentage into the average time. (There are other ways to analyze the data, but higher fidelity answers don’t change the system dynamics much.) In this case, 90 minutes / .3 gives an effective build time of 300 minutes. In this example we did try to come up with more accurate numbers, but there were frequent periods of multiple days with failed builds. A more accurate estimate of the build time was irrelevant. The team was hindered more than it was helped.
This "agile" team was "trunk-based" and "practiced CI." However, most contributors did not commit daily. As mentioned, it was common for the build to be broken for days, meaning no commits by anybody. This often ended up causing frantic changes to roll back commits, or quick patches to "fix" the build, which lead to worse code, and even more failed builds. It was a bad situation and the pressure to deliver was so high, that there was pressure to not fix the build problem. The team was losing a race, well behind, with tires on fire, being told "drive faster."
Larger commits (batch size) increase cycle time because integration will tend to take longer. Worse still, that pressure is self-reinforcing, leading away from the practice of continuous integration. In this example everybody batching up increases the average wait time from 1 to 5.5 hours or 550%. Add in merging problems and it further increases the cycle time. When things take “too long” people tend to either not get things done, or to take shortcuts. This leads to build failures, which contribute to lead times.
As suggested by this example, there’s a strong relationship between long builds and failed builds. On the other hand, frequent commits tend to lead to stable builds. Failed builds increase lead time. Stable builds decrease lead time. This is a batch size issue. It’s also a feedback issue.
It’s really a safety issue. If I am not able to make changes with decent feedback, it’s hard to work. Little fixes and cleanup become too risky and expensive, so the code rots even more, which is another contributing factor to increased cycle time.
To recap, slow builds
- Contribute to ever increasing build times
- Lead to infrequent integration
- Make minor improvements too costly to do, so code rots even faster
- Leads to more frequent merge conflicts
- Tend to degrade team morale
Hidden Costs
What makes this even worse, these transaction costs are rarely measured and indirectly noticed in the form of defective code, longer times to get work done, complaining, longer work hours, turnover, etc. The likely outcome is a death march eventually leading to the big rewrite, which is even more of a problem. This sounds like a technical issue, but this is a people issue that tends to destroy teams, erodes trust across different groups, hurts your customer relationship, and certainly hurts your bottom line.
The Big Reveal
So what’s my number? Any actual number is going to be contextual and controversial. Seconds is ideal. A few minutes is probably OK. However, when discussing with colleagues, they’ve noticed large behavior shifts moving between 12 and 8 minutes.
As a personal recent example, I switched from one cloud platform to another. The go live time went from an average of 15 minutes to around 4 minutes. This had a profound effect on my desire to simply make trivial changes and make them go live.
I’ve had a number of experiences where 12 to 8 minutes seemed like a threshold. Under that, and I feel more open to experimenting. Much more, and I’m less open to risks, which means I’m less open to learning. So maybe 10 minutes is a good target. Less time is better, and it is entirely possible even for large code bases with extensive automated tests.
This might sound impossible, but it’s not. As one extreme example, google is able to take a commit to live in production in 10 minutes (around 21 minutes in). Google is a monolith, with 25,000 developers and billions of lines of C++ code. That’s 10 minutes. While most companies are not Google, most companies do not have the size of code that Google does. So 10 minutes is a good measure to work towards.
Parting Ideas
Assuming your build time could use some attention, here are a few common ideas to get consider
- Use Legacy refactoring to make it easier to replace slow-running tests with fast microtests.
- Replace fragile tests based on test doubles and mocks with long-term reliable tests of context-neutral code.
- Move some tests out of the commit phase and into later phases in the pipeline, then make them redundant by refactoring the code and micro-testing it, finally delete the redundant tests.
- Reduce duplication in tests.
- Change system design to support test isolation.
- Increase test stability by making the product code more context-neutral and therefore more reliable.
- Buying hardware.
- …
The list goes on. Each situation, while unique, shares common goals and often several of the same techniques. At the core is a desire for frequent feedback. This allows for learning, experimentation, and avoiding big-bang integration cycles, which involved huge risk and safety issues.
Conclusion
One thing worth re-emphasizing: expect a multifaceted approach. It is likely you will occasionally have big wins, but slow and steady wins the race. Saving a minute consistently doesn’t seem like much. But 10 contributors, 1 contribution per day, 250 working days per year means that each minute saved is 2500 minutes, or roughly two person weeks. Do that daily and in a few months, you’ll wonder how you ever lived the old way.
Summary
How long should a commit-phase take?
- 10 minutes is a good target. Faster is better, a little slower is at best OK.
How can I tell if the commit-phase takes too long?
- Do developers avoid running it whenever?
- Does it feel safe to try things out?
- Do we batch things up because of the time it takes?
What’s the longest it can be and still practice continuous integration?
- At the turn of the century: Length of day / number of committers
- Now: multiple commits, to trunk, for each person/pair is the norm
Making change stick
- Instilling dissatisfaction with current build times tends to enable continuous improvements (learning to see waste)
- When you reduce it beyond certain thresholds, you’ll get tangible behavior changes. Celebrate those.
- Improving build times will require many techniques. Try ideas that offer small gains.
What can I do if our build is too long now?
This is the challenge. Don’t think in terms of fixing it immediately. Think long term. Take the time to figure out where the time is being spent, and work on fixing that. Maybe you find slow running tests that are fully integrated. You might need to do some legacy refactoring to be able to better isolate tests. Maybe the build time is waiting for a shared resource. Can you duplicate it or remove it from most of the tests? Maybe the build server is overloaded. Can you duplicate it? Whatever is taking the time, work on that. Then work on the next thing. As you work on the total time, the feedback time goes down. As that happens, things have a chance to improve. Play the long game here. If necessary, you can perform some simple calculations to see how much the slow build is costing in developer time. Then ask the question: What will it cost to wait to fix the build problem? This cost is invisible, make it visible.



